Парсинг Scrapy в облаке Zyte Python
Расскажу вам про облачный парсинг Zyte и его возможности. Спайдеры - это задания фрейворка Scrapy для парсинга сайтов, API. Я слышал про облачный парсинг и хотелось попробовать. Вот я и попробовал. Мне понравились результаты работы облачного парсинга.

Для начала вам нужно создать задание или спайдер. Вы можете скопировать готовое задание. Далее вам нужно запустить его локально и посмотреть на работу. Задача должна хорошо работать и ваш код не должен содержать ошибки. Перед отправкой задания в облако происходит проверка код всего приложения и облако не примет код с ошибками.
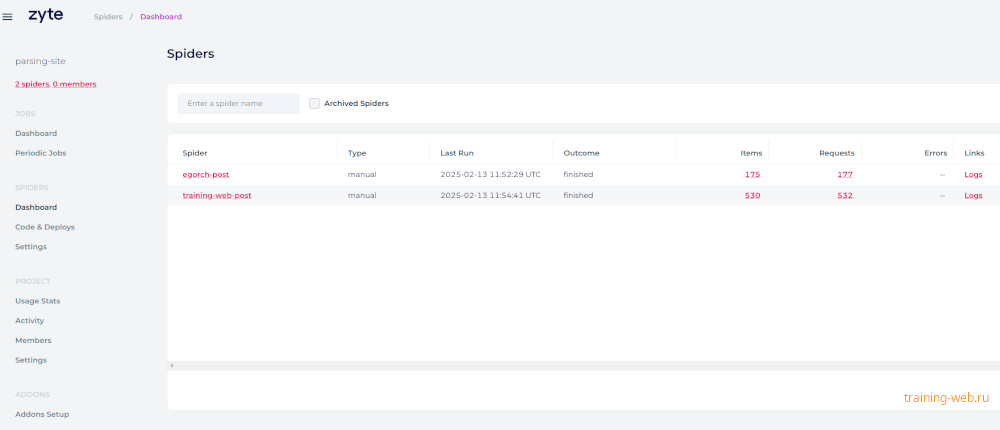
Далее вам надо зарегистрироваться в zyte.com. Вам в итоге нужно получить API key. Смотрите статью Deploy and run on Scrapy Cloud. После этого закачайте необходимые библиотеки для работы с облаком и отправьте код в облако при помощи команды shub deploy project_id. Как только произошла успешная отправка кода, вы сможете запустить в облаке ваши спайдеры задачи. Вы сможете скачать результаты работы задач в json, csv, xml форматах.
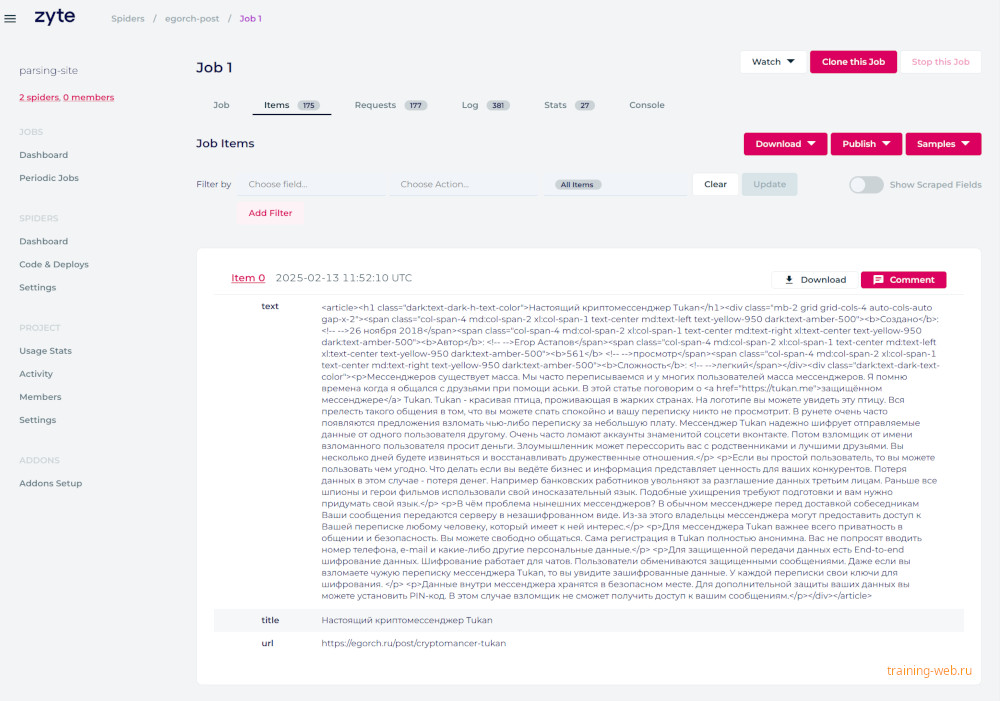
Даже можете скачать данные из облака в вашем cкрипте при помощи запроса.
# GET запрос
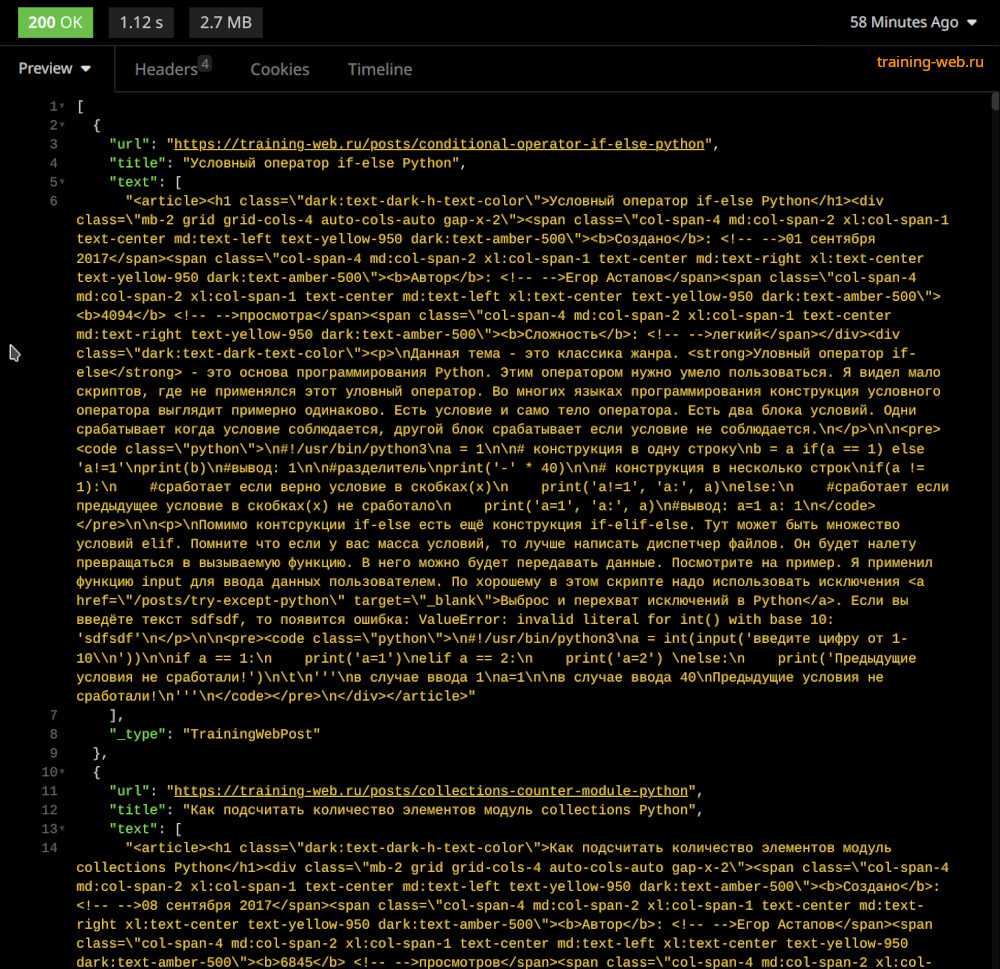
https://storage.scrapinghub.com/items/job_id?apikey=api_key&format=csv&fields=key,name,price,url&include_headers=1Посмотрите на картинку. Тут простой запрос который выводит работу job.
Кто-то из вас скажет а зачем все это надо и зачем связываться с облаком? Я отвечу простым ответом. Вам для работы парсинга нужен боевой сервер VDS. Он примерно стоит 400-500 рублей. Вы должны уметь настраивать крон или sheduler. У вас должны быть разные IP-адреса proxy подключений для замены внутри парсера на случай бана. Каждый ip стоит денег. API от zyte автоматически сменить забаненный IP. Тут вам не нужно переживать. Читайте статью Zyte API shared features.
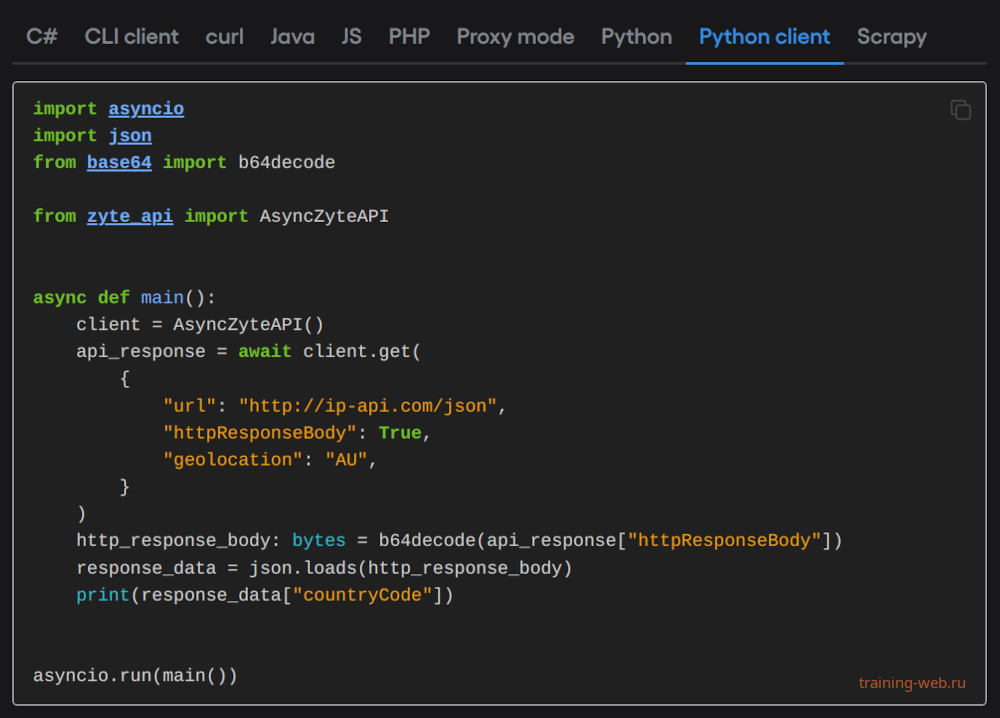
Вы для скачивания результатов парсинга должны делать API или давай пароли от FTP-соединений. Если вы сделали апи для отправки данных в формате json, то вы должны выдавать данные по логину и паролю. Даже можно сделать полноценную авторизацию. Отдавать конфиденциальные данные всем подряд - это нехорошо. Самая главная фишка - это AI искусственный интеллект. Он поможет вам искать в тексте нужную информацию. AI легко переведёт текст html в данные json. Он может структурировать данные по смыслу. Можно сделать самому такое решение, но на это уйдёт время.
Вы можете даже запустить облачный скрипт из своего скрипта. Даже такое можно сделать. Это удобно. Можно даже с фронта написанного на ReactJS, VueJS отправить запрос, который запустит скрипт для парсинга в облаке.